TAB 2021 겨울방학 학회활동 [슬기로운 코딩생활]
3주차 TIL입니다.
작성자 : 37기_강다인
이번 슬기로운 코딩생활 시간에는 CNN Application에 대해 공부했습니다. 병행해서 하고 있는게 많아서 어째 TIL에 올리는게 통일성이 없지만,,,
1. Tour of ConvNet Architectures
2012년부터 imageNet이라는 데이터 셋에 대한 정확도를 높이는 대회를 열고 있는데, AlexNet이라는 모델의 performance가 우승했다.
ImageNet
ImageNet Large Scale Visual Recognition Challenge

categorie를 기준으로 Clssification, Localization, Detection track으로 문제를 품
2010년 쯤까지는 shallow network가 우승했었는데, 2012년 8 layers로 구성된 AlexNet이 deep nn으로 첫 우승을 차지함.
AlexNet
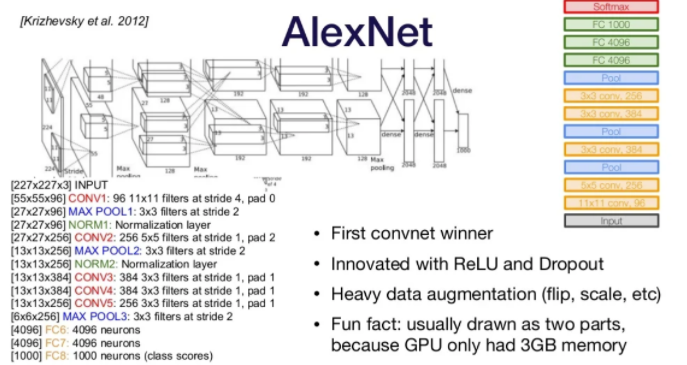
LeNet과 유사함. ReLu와 Dropout을 활용한 모델이고 이미지의 색, 각도 등을 조정하여 데이터 수를 늘리는 Augmentation기법을 활용함. Dropout은 일부 데이터를 0으로 영향을 덜어내는 기법.
두 개의 부분으로 구성되는데, GPU 메모리 부족으로 저렇게 만들었다. 파라미터=~60M
ZFNet
AlexNet 다음 해에 우승한 모델
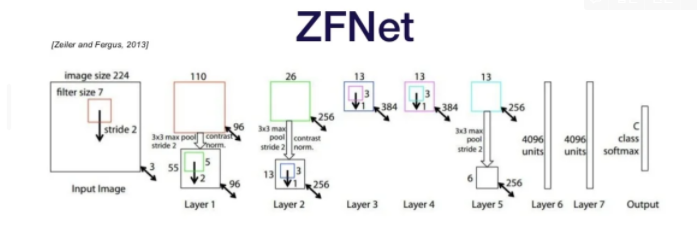
AlexNet과 몹시 유사함. 그런데 filter size를 conv1에서 줄이고, Conv3, 4, 5에서 채널을 늘림으로써 error를 5%나 감소시킴.
중간 레이어를 deconvolution시켜서 원본과 비교하는 방법을 도입함.
각 필터는 image의 일부의 특징(타입)을 뽑아낸다. 좀 더 앞에 있는 layer들이 원본 pixel에 가깝다.
VGG

VGG는 무려 19개 레이어로 구성된다. 오직 3x3 conv layer만 사용한다.(stride-1)
채널의 차원은 layer마다 증가한다. 원본 pixel에 가까운 앞쪽 layer도 3x3 conv layer이고, 뒤도 마찬가지이다. 앞에서는 64차원이다가 뒤로 가면 512 차원이 된다.
3x3 conv layer을 쌓다 보면 큰 conv layer과 똑같은 필터 유효범위(receptive field)를 얻게 된다. 파라미터 수는 줄이면서! ⇒ 빠른 학습 가능
메모리는 대체로 앞쪽 레이어에서 많이 쓰인다. input 이미지의 크기가 크기 때문에, 실제로 convolution은 전부 행렬계산이라...

대부분의 parameter는 뒤쪽에 오는 fully connected layer에서 생긴다. 각각 다른 위치에서 쭉 펴내고 nn으로 학습시키므로...
아무튼 파라미터를 그냥 9x9 conv를 쓴 것보다 훨씬 적게 사용하면서 같은 성능을 낼 수 있다.
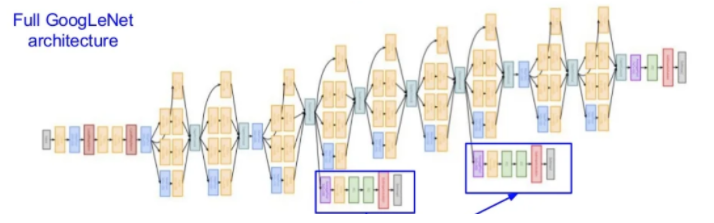
GoogLeNet

VGG만큼 깊지만 파라미터 개수가 VGG의 3% 수준밖에 되지 않는 비약적인 성능을 보여줌.
FC layer가 없음
Inception module(conv-pool-conv-pool-...)
여러 개의 conv에 넣고(서로 다른 module들) 결과를 concat하도록 함.

inception 가설은 (depth dimension)채널간의 상관분석이다. convNet의 input은 channel의 수 만큼의 깊이를 가지고 있다가, layer가 지나가면서 channel이 늘어난다.
이때 1x1 conv layer을 사용하면 연산량을 지나치게 늘리지 않으면서 channel을 원하는대로 조정할 수 있다.
additional inject classifier gradient
끝에만 classifier을 다는 게 아니라 중간 layer에서도 gradient를 얻도록 했다.
ResNet

- problem : layer가 깊어질수록 기울기 소실 문제가 발생하여 마냥 성능이 좋아히지 않음.
- solution : 몇 개의 layer를 skip하여 값을 전달하도록 해서 해결함.
- max pool을 쓰지 않고 filter의 개수와 깊이만 늘려감.

Residual Net Variants

- DenseNet은 skip layer을 더 많이, 광범위하게 적용시킴
- ResNeXt은 inception과 ResNet을 합친 것
SENet(Squeeze-and-Excitation)
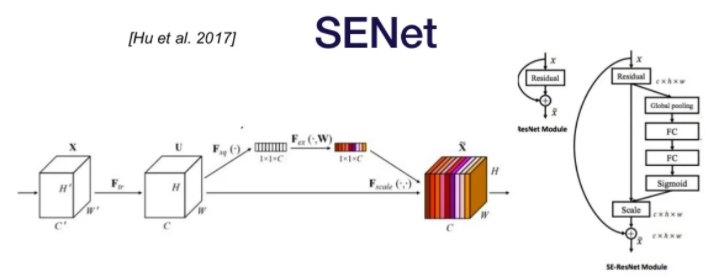
global pooling + FC 모듈을 추가(SE Block이라고 함). conv를 거친 feature map U에서 C개 채널의 2차원(HxW)의 feature map을 1x1 사이즈로 global average pooling을 실행해준다.(채널마다 평균내어서 하나의 값을 얻는 것)
'21 - 2학기 > 슬기로운 코딩생활' 카테고리의 다른 글
| [TIL]3주차 바닐라JS(3)_momentum 클론코딩 (0) | 2022.01.19 |
|---|---|
| [TIL] 유니티2d로 게임 개발 3주차 (0) | 2022.01.19 |
| [TIL]3주차:프로젝트 홈페이지 만들기 (0) | 2022.01.18 |
| [TIL]2주차 크롤링과 봇 개발 (0) | 2022.01.12 |
| [TIL] .Net 설치 및 기존 프로그램 연동 (0) | 2022.01.12 |


